

Will We Get Wise Enough Fast Enough?
On AI for Human Reasoning
1 min read
This post is based on a talk I gave at The Curve in October 2025. You can watch it below or at this link. I gave this talk to an audience that generally expects AI to become powerful quite soon. If you're skeptical of that timeline, I'd still encourage you to engage with the core question: even with today's AI tools, can we build systems that help humans reason better—and can we do it fast enough to matter?
Two Visions
Let me start with two visions. Imagine you have a question about the future—say, "What would happen if California tried to secede from the US?"
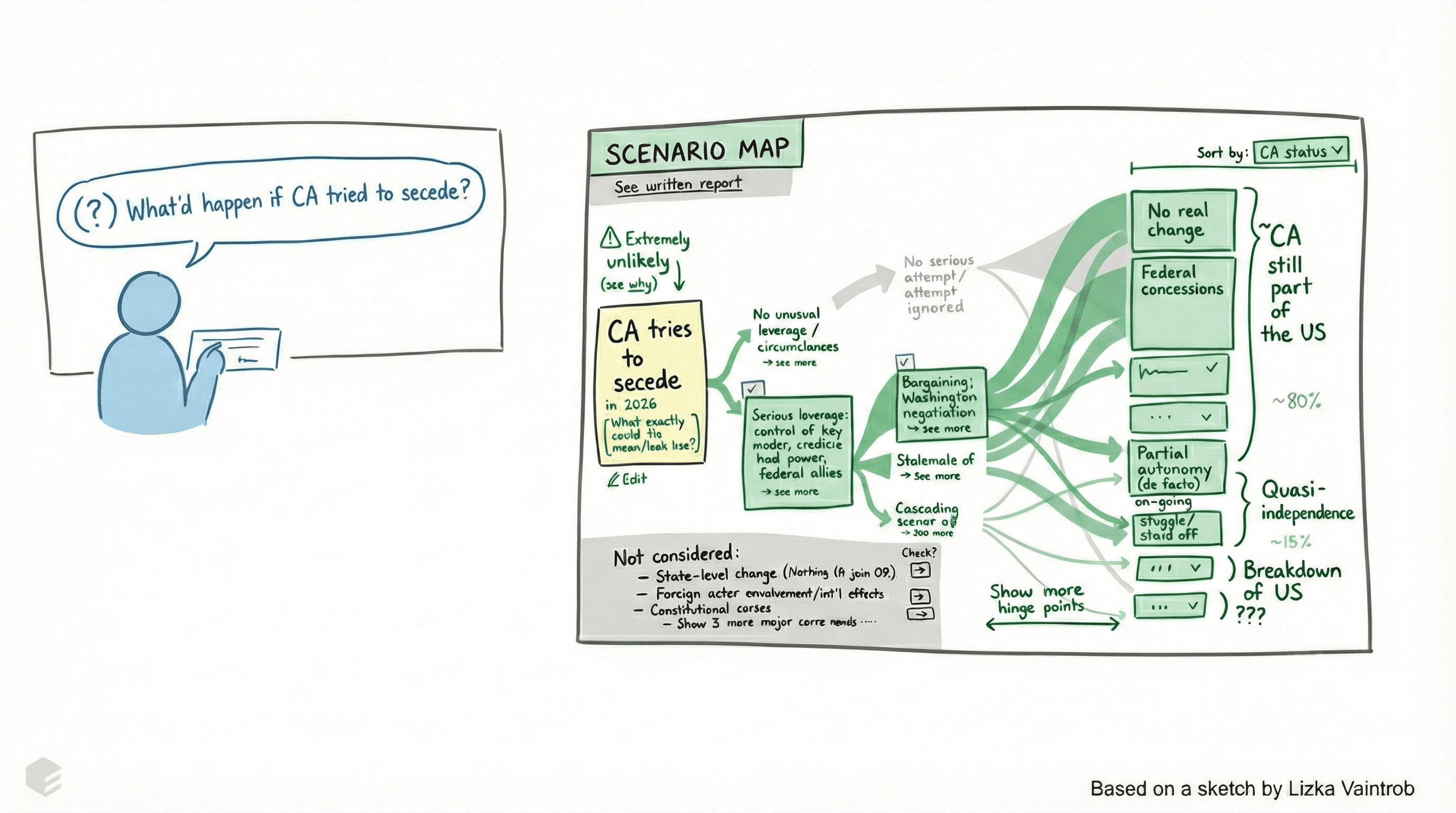
You type it into an AI system. The system operationalizes the question in a few different ways, checks with you, and then shows you a sequence of forecasts and conditional forecasts. Here are the different trajectories: some lead to no real change, some lead to federal concessions, most (maybe 80%) lead to California still being part of the US. You can zoom into intermediate steps if you want. Everything is laid out clearly. And this works reliably for any question you have about the future.
Wouldn't that be nice?
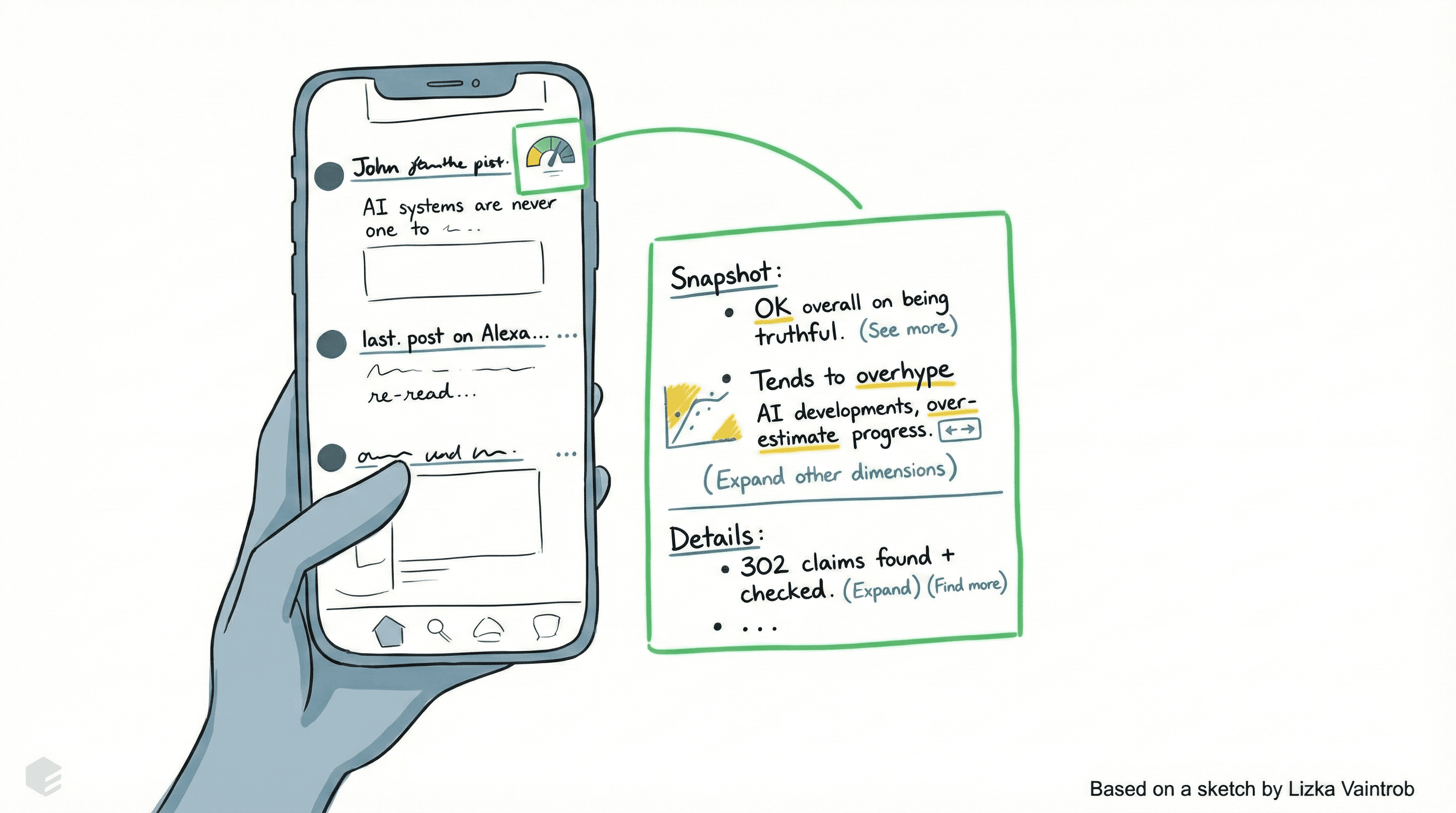
Here's a different vision. You're on the platform formerly known as Twitter, and you're unsure how reliable different people are. But next to every person, you see a reliability indicator: "This person is pretty truthful overall, tends to overhype particular AI developments, sometimes overestimates progress—based on 300 claims we've found and checked." You can look into the details if you want. For any person you care about, you can figure out how truthful they tend to be over time.
These are two specific visions I really like. But they're part of a bigger dream.
The Dream

The bigger dream of AI for human reasoning is something like this:
Get really good at predicting and exploring the future
Get really good at aligning on what's true as a society
Build tools for better-advised decision-making
Enable easy negotiation and trusted agreements
Support good governance and oversight
In some sense, if you could do all of these, you're kind of done. That's more or less the whole problem.
The important thing about this dream: this is not a dream about superintelligence. A lot of these tools you can build today with current AI. Many people are doing so.
I could stop here and say: "Look, it's a beautiful dream, we're building it, it's great." But let me zoom into some details, because there's a question I keep asking myself: Will AI make us wise enough fast enough?
That has two parts: the "fast enough" part and the "wise enough" part.
Fast Enough
Let me start with "fast enough" since it's the easier component.
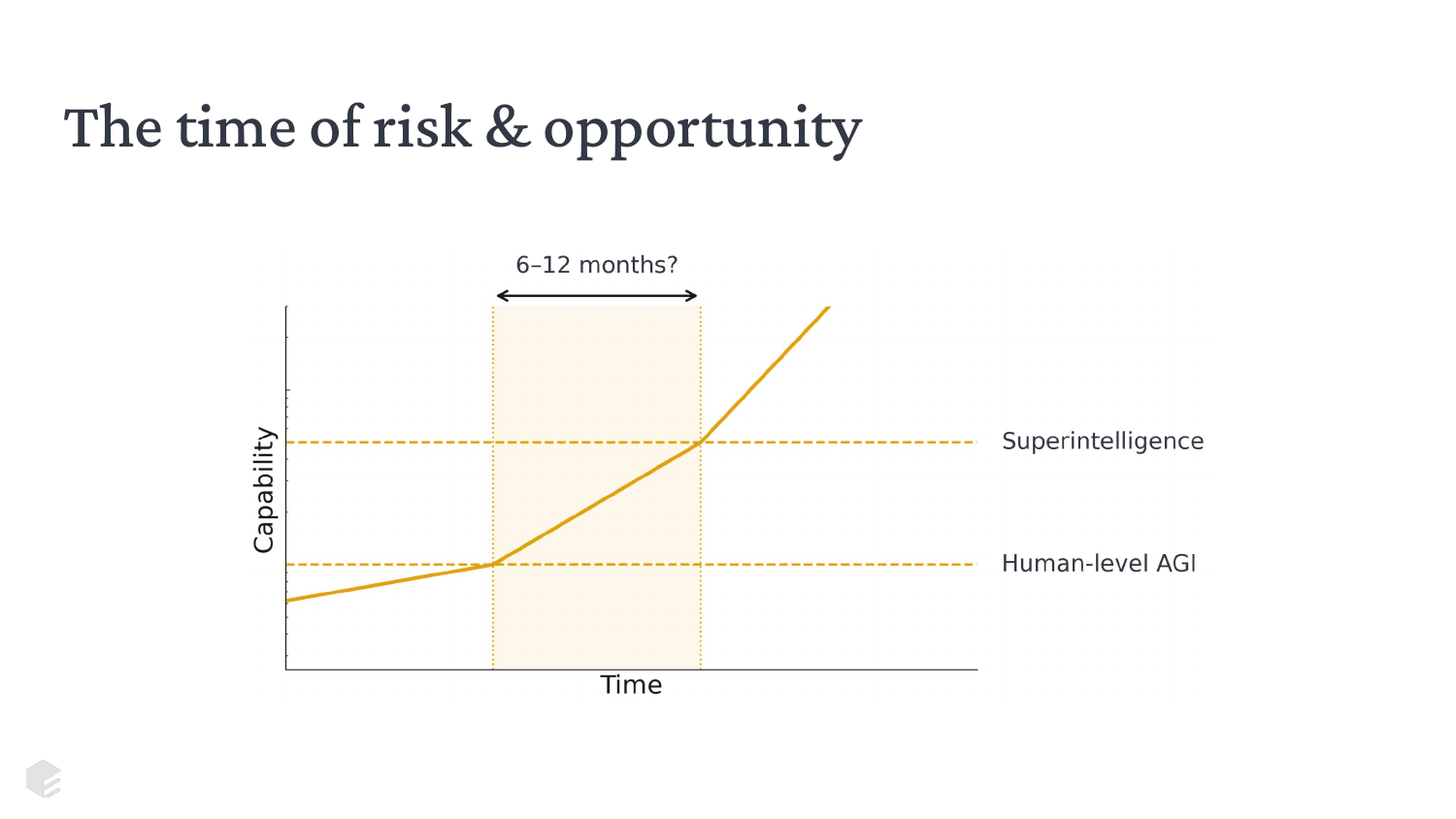
A lot of people probably have a mental picture that looks something like this: We're somewhere before human-level AI. At some point we'll have it, then progress will accelerate because AI will be deployed toward doing more AI research. Then a period of risk and opportunity starts—you can do vastly more work than before, but you might not have long (maybe 6-12 months?) until you're at superintelligence, and then all bets are off.
If you couldn't make progress on the beautiful vision before that time of risk and opportunity, things might be pretty tough.

The basic pitch on risk: AI does AI research, progress accelerates, that could lead to a vast amount of AI thinking, and it might just be hard to keep up—unless you specifically build tools to keep up. Especially if you're doing long-horizon reinforcement learning training that's easy to optimize for legible metrics, that might lead to unintended side effects. The metrics look good, but how exactly did it get there? Did it do things along the way you couldn't control for?
So there's something that must be done that's different from AI training by default if you want to avoid these risks.
The more specific question I ask myself: We're kind of setting up the chessboard now for that future. What can we do so that our ability to understand the world and steer it grows faster than our ability to just accomplish stuff in the world—and to disrupt it and destroy it?
The good news: a lot of people are actually trying to make progress on this.
A Taxonomy: Raising the Floor vs. Raising the Ceiling
I'd break down the work into two categories:
Raising the ceiling: Projects trying to push the frontiers of human understanding and wisdom—doing better than any human is doing right now
Raising the floor: Projects trying to improve epistemics across the board, making everyone in society better at reasoning
Some projects are in between or try to do both. But let me use this taxonomy to talk about some specific projects.
Raising the Floor
Community Notes for Everything
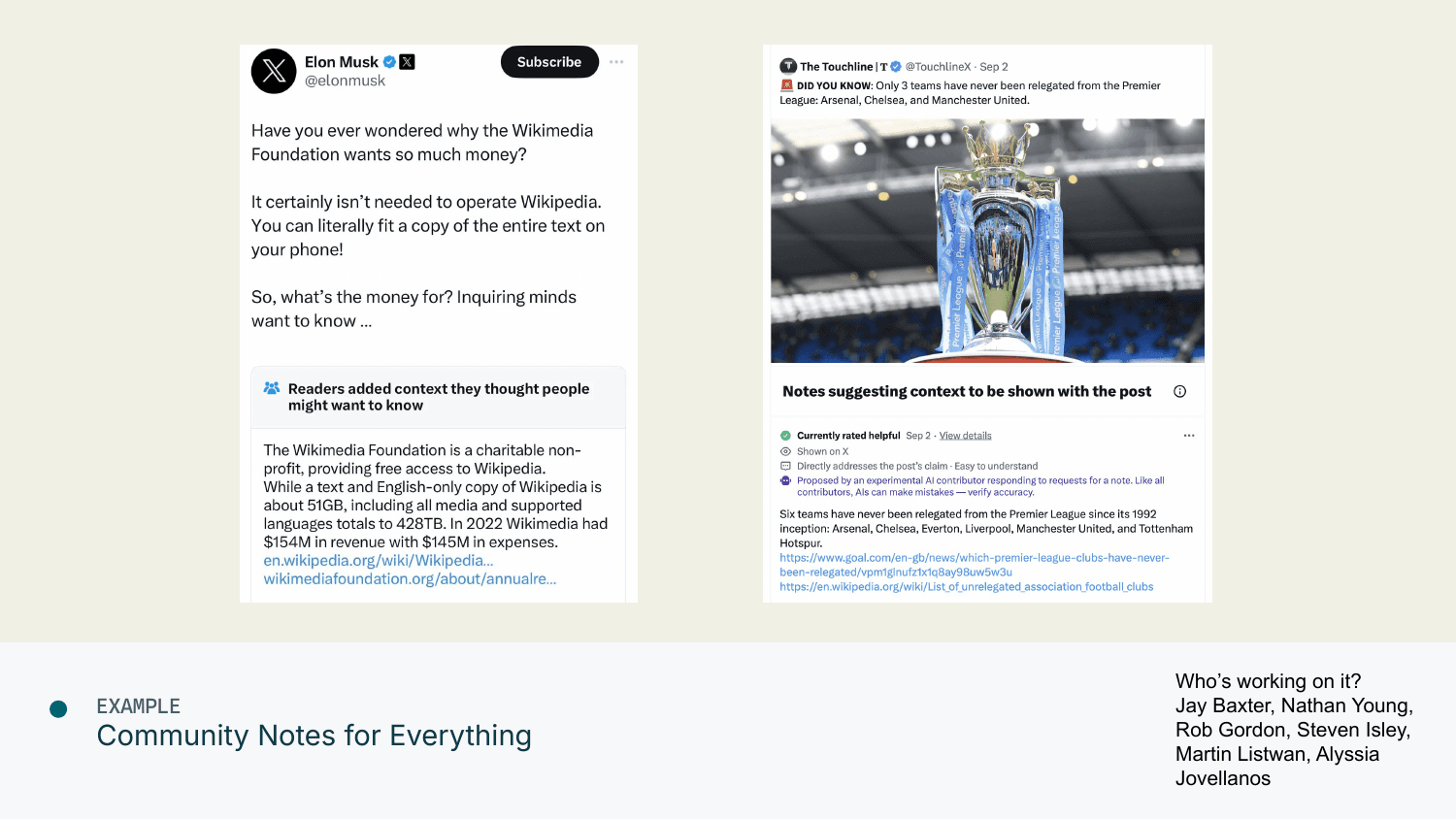
Most people have seen community notes on X—reader-provided context with an algorithm that rewards disagreement. The important thing to highlight: we now have the first AI-written community note that actually got accepted.
This is exciting because a main constraint for community notes is that humans have to write them, and there's just a lot of stuff you could want to annotate with relevant context. If you can automate both creation and voting, you could have community notes on literally every post on social media platforms.
And nothing constrains this to just X. You could have a Chrome extension or some other way of interfacing with content more broadly. Whenever you look at a claim or piece of content, something tells you: "Here's context that, if you knew it, would make you interpret this differently."
I would personally like that when I look at a news website.
Part of this is a technical problem. Part of it is an adoption problem. Not just: how do we build this? But: how do we get it into the world?
Epistemic Virtue Evals for LLMs
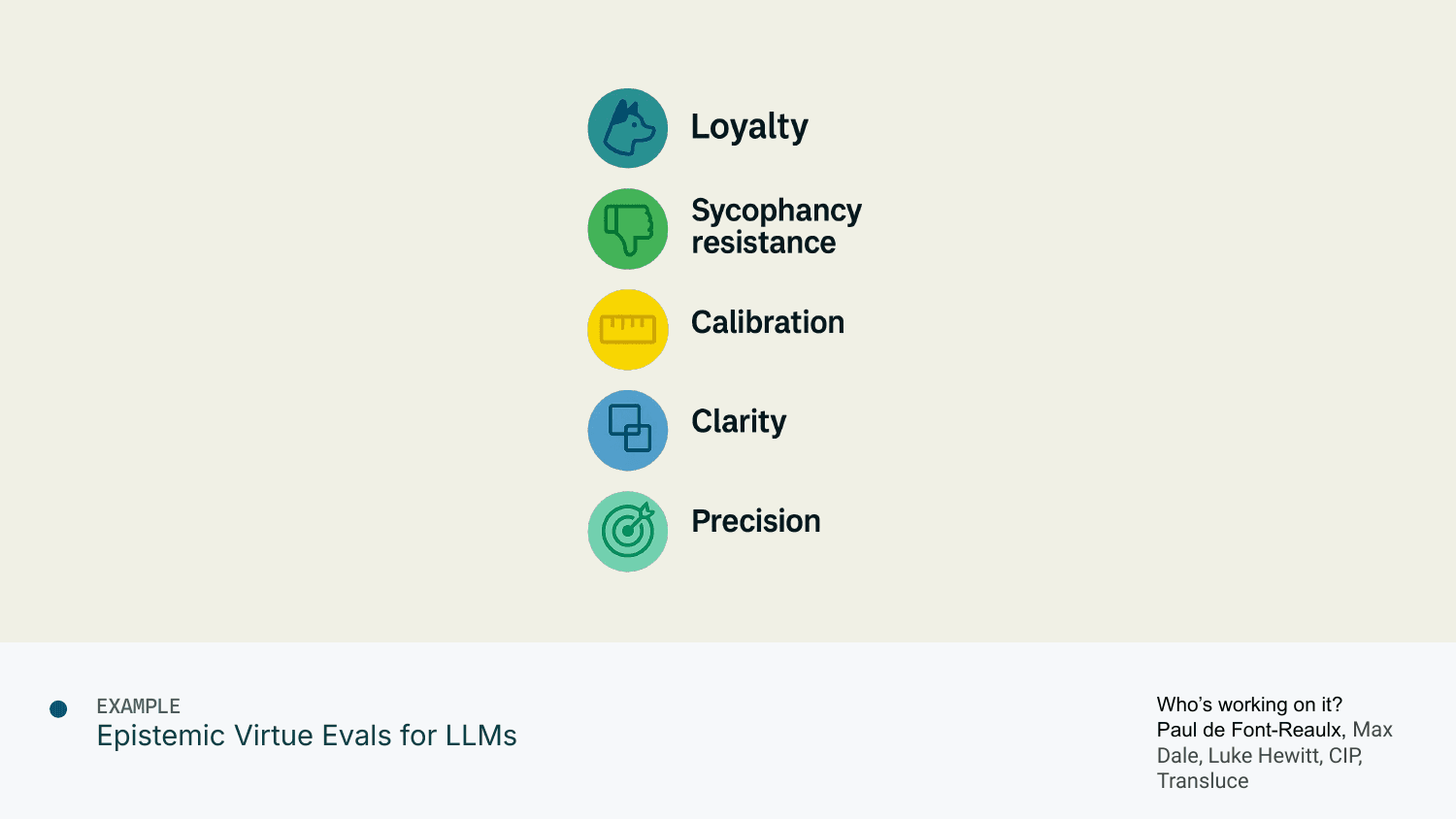
Right now there are tons of benchmarks for language models. But I'm surprised there isn't more on epistemic dimensions.
For example, you could write a really good eval that checks: Is ChatGPT more loyal to OpenAI than to other providers? If you ask it questions, is it biased toward being positive about OpenAI? That would be good to know—it might change whether you ask it. And it would create incentives for the organization. OpenAI probably doesn't love it when a benchmark shows bias toward them.
Other dimensions:
Sycophancy: People are more aware of this now, but I don't know of a global dashboard showing exactly how sycophantic every model is and how it's trending over time
Calibration: When a language model says something is 70% likely, does that thing happen 7 out of 10 times? Currently it's pretty easy to push models around—you say "have you considered this argument?" and they say "wow, you're right, this updates me completely." That shouldn't happen.
Clarity: How often does the model hedge and say things like "there's a real plausibility this could happen" where you can interpret it as more or less anything?
Precision: Can you fact-check all the claims in the model's response and see what fraction are actually true?
A few people have started working on this. I think many more could contribute, and it could make things much better. Again, part is technical, part is adoption—you want to make it but also let people know you made it. Labs will change their approaches partly because these things become widely known.
Raising the Ceiling
Mediation and Consensus Building
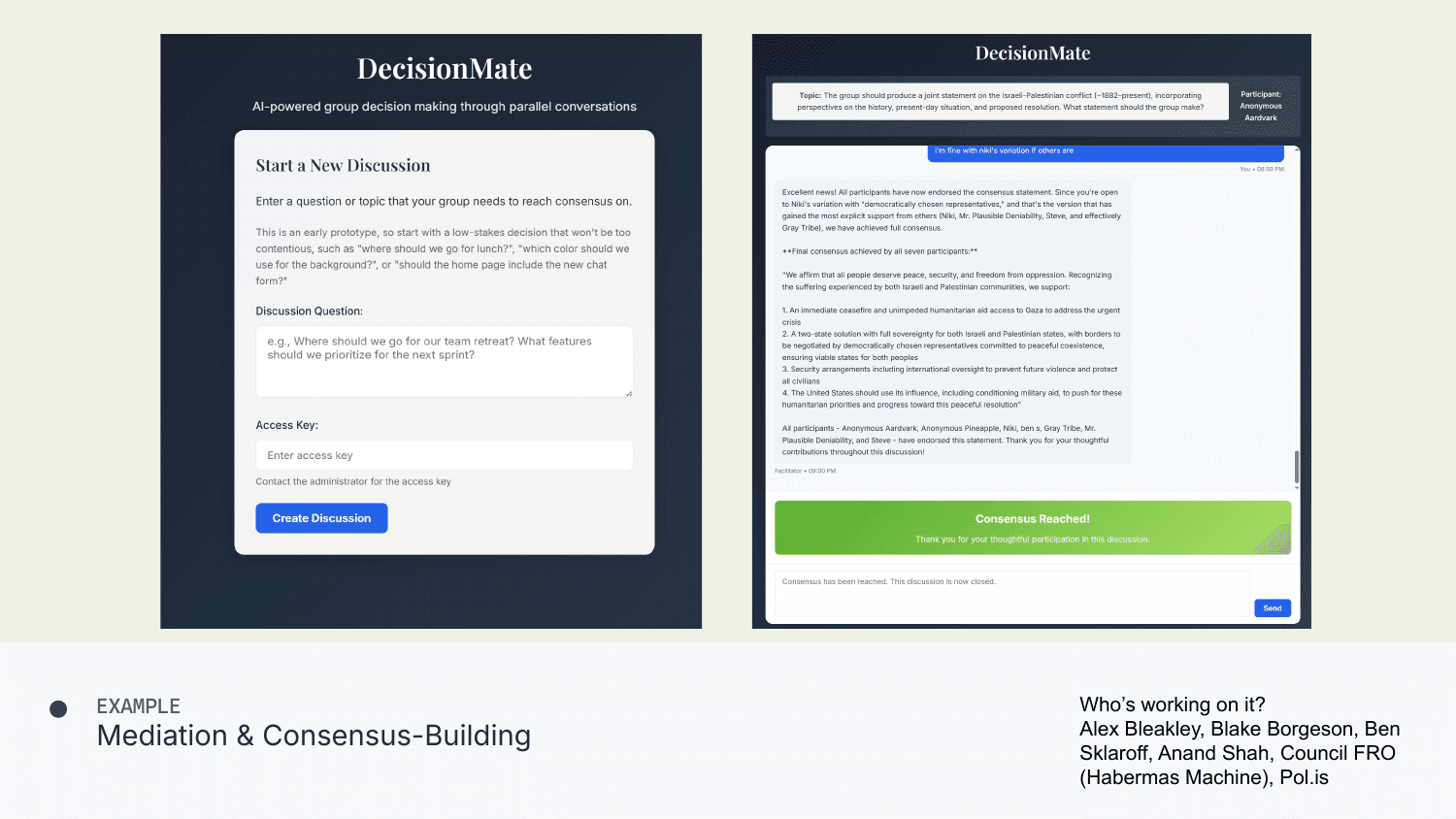
There's a project called Decision Mate working on this. The idea: you have a group trying to decide something—say, whether to take questions after a talk. You could all debate it, but it gets chaotic. The people who shout loudest get listened to most.
Instead, you could have an AI system that talks to everyone in parallel, tries to understand what they want, acts as a neutral arbiter, shuffles relevant information back and forth, and ultimately helps people reach a consensus everyone is happy with.
That's at a small scale. You could imagine similar things at much broader scales—rethinking how democracy works, or anything in between.
Scaling Scenario Modeling
Another project I think is really cool: scaling up scenario modeling.
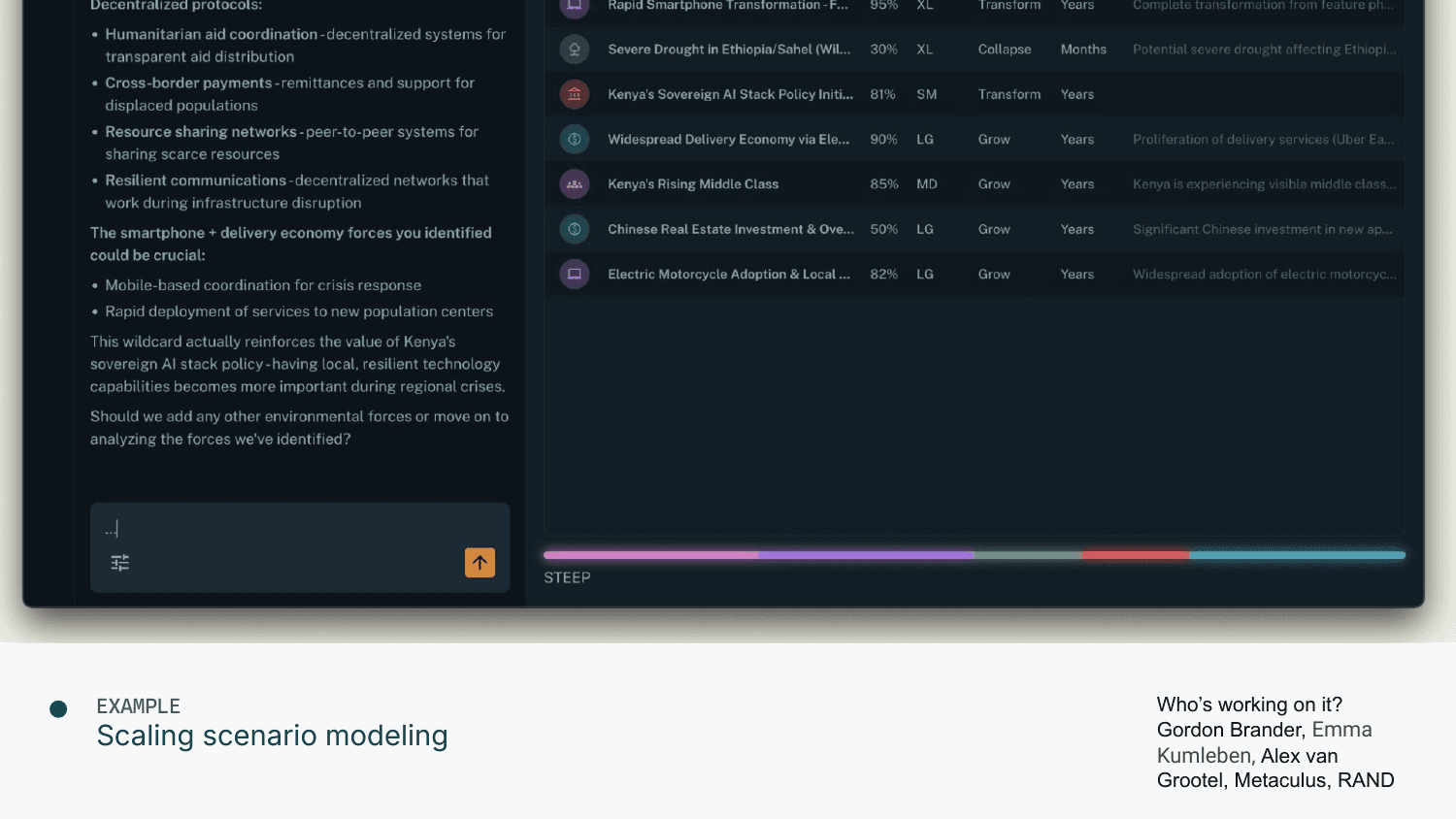
Say you're trying to think about what's going to happen with Kenya. If you're a think tank, you probably apply some framework—what are the social factors, technological factors, economic factors? For each category, break it down into subcomponents. For each thing, think about how important it is, how likely, in what direction it pushes future developments.
I'm excited about this because it leverages what machines are uniquely good at: going over a large list of things and for each one thinking carefully about whether it's important and what the evidence is.
Even with present-day technology, this could produce tools for understanding scenarios that are better than what any human can do—just because humans are so limited in how much evidence they can look at.
The ultimate vision would be something like AlphaGo or AlphaZero for scenario planning: an incredibly large tree of things that could happen, ways people could respond, and superhuman ability to plan for those scenarios.
Elicit: Evidence-Based Decision-Making
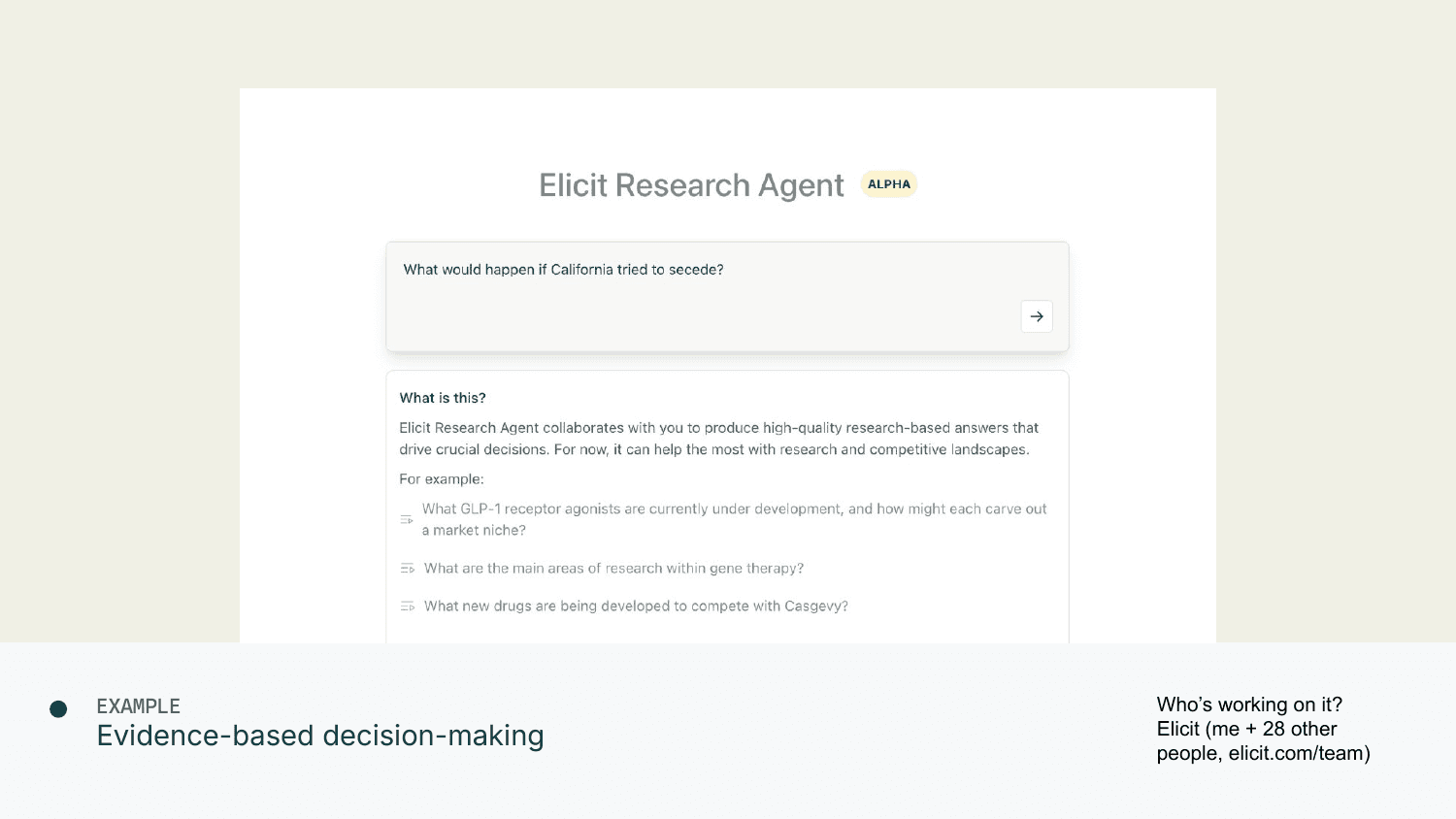
This is what I'm personally working on as CEO and co-founder of Elicit. We mostly help people understand and interpret the scientific literature, though we're trying to make that much broader—moving from the "evidence-based" part toward the "decision-making" part.
Here's an example from a work-in-progress version. If I enter "What would happen if California tried to secede?" it asks clarifying questions—which sources are relevant (federal statutes, Supreme Court cases, government reports)? What aspects of outcomes do you care about (legal precedents, federal responses, timelines)?
Then you get a response: here are different outcomes (blocked in court, federally suppressed, negotiated constitutional succession). For each, what's the probability estimate, what are the political consequences, what's the likely timeline?
Behind the scenes, Elicit makes a plan: search these sources, use this method to extract relevant data, aggregate in this way, make canonical scenario groups, draft rows, filter them. If you want to understand why you're looking at this table and not some other table, you can look into the process that generated it. And if you click on anything, it tells you the data for why—here's the quote from the relevant citation.
Most people use Elicit for more traditional questions in biomed or pharma, like "What's the burden of disease for antimicrobial resistance?" But the principle is the same.
What Can You Do?
Three options:
Question the dream. Is this even a natural category? Does the dream make sense? Will this all just happen automatically as a result of AI progress? I'd be curious about this—if the dream is wrong, I don't want to work on it.
Build the technology. There's quite a lot to build. You can join Elicit or other projects working on this.
Help with adoption. This might be the most important one. The timeline to transformative AI might not be that long, and the state of epistemics in the world is not great right now. If we want this stuff to be well on its way to being implemented by the time we automate research and product development using AI, things will have to change fast.
So What?
The title question was: Will AI make us wise enough fast enough?
I don't know the answer. But I think the question matters, and I think a lot of people can contribute to making the answer "yes."
The tools exist to start building this now. The technical problems are interesting but tractable. The adoption problems are hard but not impossible.
And the alternative—a world where our ability to do stuff outpaces our ability to understand and steer—doesn't seem great.
References
Thanks to Owen Cotton-Barratt, Lukas Finnveden, and the Elicit team for helpful feedback, Lizka Vaintrob for sketches of the future, and Ben Goldhaber and the FLF team for supporting many projects in this space with their AI for Human Reasoning fellowship.


