
AI for Scientific Research
AI for Scientific Research
This video demonstrates Elicit's report generation workflow. A researcher types a research question, Elicit searches through millions of academic papers, and automatically generates a structured research report with citations in seconds.
TRUSTED BY OVER 5 MILLION RESEARCHERS, INCLUDING AT
TRUSTED BY OVER 5 MILLION RESEARCHERS, INCLUDING AT
TRUSTED BY OVER 5 MILLION RESEARCHERS, INCLUDING AT

Stand on the shoulders of giants
Use Elicit to understand more quickly what science already knows, so that you can discover the unknown.
Research takes many forms
Whether you need a quick answer or are planning a multi-month comprehensive review, Elicit can support you from beginning to end.

Search
Search over 138 million academic papers and 545,000 clinical trials, with more data sources coming soon.
•
Elicit's semantic search means you don't have to know all the right keywords to get relevant results.
•
Search
Search over 138 million academic papers and 545,000 clinical trials, with more data sources coming soon.
•
Elicit's semantic search means you don't have to know all the right keywords to get relevant results.
•

Research reports
Elicit generates high-quality research briefs based on a process inspired by systematic reviews.
•
Unlike with other AI tools, Elicit Reports can be deeply customized. You can change which papers and what information is covered in the reports.
•
Research reports
Elicit generates high-quality research briefs based on a process inspired by systematic reviews.
•
Unlike with other AI tools, Elicit Reports can be deeply customized. You can change which papers and what information is covered in the reports.
•

Systematic literature review
Elicit can automate screening and data extraction of systematic reviews, while partially supporting search and report generation.
•
Researchers report up to 80% time savings using Elicit for systematic reviews.
•
Systematic literature review
Elicit can automate screening and data extraction of systematic reviews, while partially supporting search and report generation.
•
Researchers report up to 80% time savings using Elicit for systematic reviews.
•

Library
As you use Elicit, store and organize the sources that you find so that you can easily reuse them in future projects.

Alerts
Research is constantly evolving; use Elicit Alerts to stay on top of new research without cluttering your inbox.
How we’re different
There are a lot of AI tools out there. What makes Elicit unique?
Scale
Elicit can find up to 1,000 relevant papers and analyze up to 20,000 data points at once.
Accuracy
Elicit is the most accurate AI product for scientific research. Learn about how we validated Elicit's accuracy.
Transparency
Elicit supports all AI-generated claims with sentence-level citations from the underlying sources.
More than chat
Elicit goes beyond chat to provide rich, interactive tables and multi-step workflows.
How we’re different
There are a lot of AI tools out there. What makes Elicit unique?
Scale
Elicit can find up to 1,000 relevant papers and analyze up to 20,000 data points at once.
Accuracy
Elicit is the most accurate AI product for scientific research. Learn about how we validated Elicit's accuracy.
Transparency
Elicit supports all AI-generated claims with sentence-level citations from the underlying sources.
More than chat
Elicit goes beyond chat to provide rich, interactive tables and multi-step workflows.
How we’re different
There are a lot of AI tools out there. What makes Elicit unique?
Scale
Elicit can find up to 1,000 relevant papers and analyze up to 20,000 data points at once.
Accuracy
Elicit is the most accurate AI product for scientific research. Learn about how we validated Elicit's accuracy.
Transparency
Elicit supports all AI-generated claims with sentence-level citations from the underlying sources.
More than chat
Elicit goes beyond chat to provide rich, interactive tables and multi-step workflows.
We live in a scientific world
Elicit supports researchers across many domains and industries
Pharmaceuticals
Bring novel drugs to patients faster
Academia
Push the frontier of science forward
Medical devices & technology
Design safe and effective products for patients
Policy & government
Make evidence-based policies
Consumer goods
Improve products that billions rely on every day
Industrials
Discover new materials and engineer them at scale
Example report
Software & technology
Innovate on user experience, algorithmic performance, and more
Example report
We live in a scientific world
Elicit supports researchers across many domains and industries
Pharmaceuticals
Bring novel drugs to patients faster
Academia
Push the frontier of science forward
Medical devices & technology
Design safe and effective products for patients
Policy & government
Make evidence-based policies
Consumer goods
Improve products that billions rely on every day
Industrials
Discover new materials and engineer them at scale
Example report
Software & technology
Innovate on user experience, algorithmic performance, and more
Example report
We live in a scientific world
Elicit supports researchers across many domains and industries
Pharmaceuticals
Bring novel drugs to patients faster
Academia
Push the frontier of science forward
Medical devices & technology
Design safe and effective products for patients
Policy & government
Make evidence-based policies
Consumer goods
Improve products that billions rely on every day
Industrials
Discover new materials and engineer them at scale
Example report
Software & technology
Innovate on user experience, algorithmic performance, and more
Example report
Latest releases






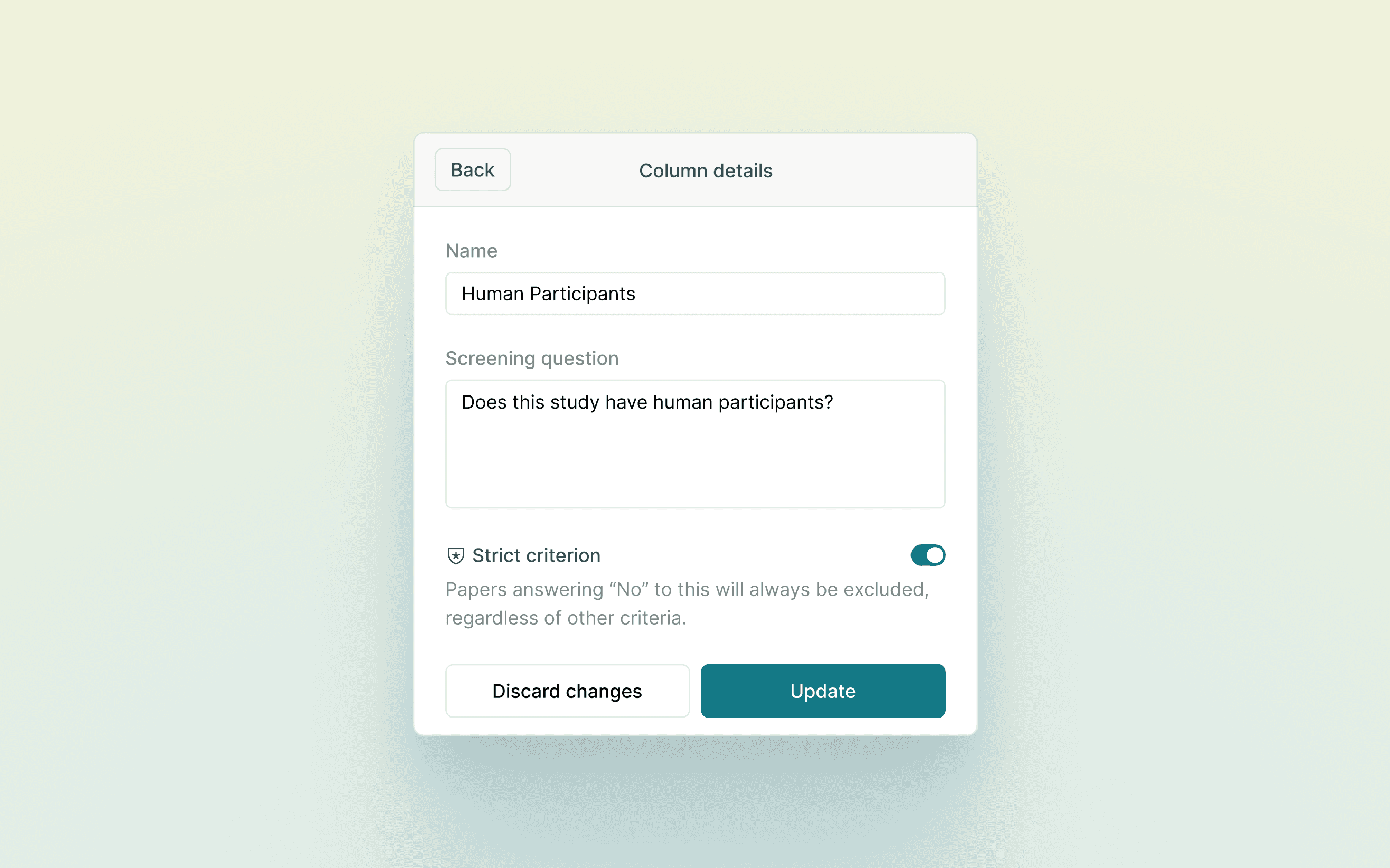

Latest releases
Latest releases
Trusted by top research institutions
Our team and our customers have rigorously tested and evaluated Elicit's accuracy



Trusted by top research institutions
Our team and our customers have rigorously tested and evaluated Elicit's accuracy
Trusted by top research institutions
Our team and our customers have rigorously tested and evaluated Elicit's accuracy
This is an important moment in time
AI has the potential to significantly change the world. Change is complicated. As researchers and scientists, we must direct this technology towards having as positive an impact as possible. We need to move quickly, without sacrificing quality. Our research needs to be more dynamic to stay relevant in a rapidly-changing world.
Scientific rigor, good reasoning, and high-quality research are more important than ever.
We built this to help you. To help you understand the never-ending mysteries of our universe. To help you make breakthroughs that end disease. To help you wrestle with hard questions about how to alleviate poverty, explore new frontiers, or create thriving communities.
Thank you for your curiosity. Your sense of wonder. For your uncompromising commitment to truth and progress. We hope we can make finding that truth just a little bit easier.